「ゼロから作るDeep Learning ❷ ―自然言語処理編」のまとめ 後半
の続き
5章 リカレントニューラルネットワーク(RNN)
言語モデル (Language model)
m個の単語が並んだ文章を単語の同時確率として表すと乗法定理より以下のように表せる。
前半で扱ったword2vecのCBOWモデルでは、予測する単語の両側をコンテキストとして用いていた。
左側の単語のみを用いるようにすれば、(1)の式を近似して表せる。
例えばウィンドウサイズ2だと
ただこれだと、word2vecの中間層では単語の並びは無視されるので長い文章の場合予測が困難。
そこで登場するのがRNN
(実際はRNNによる言語モデルが登場したのが2010年。RNNで単語の分散表現を獲得するのが行き詰まっていたところに、word2vecが2013年に登場した。CBOWモデルは本来言語モデルではないので、この本では無理やり言語モデルに適用してみて話を進めただけとのこと。)
RNNはループ経路を持つ。時系列を扱える。
を隠れ状態として出力する。
は次の時点の同じレイヤーに入力される(ループ)。
RNNの逆誤差伝播はBPTT(Backpropagation Through Time)と呼ばれる。
しかしこのままだと計算リソースが膨大だったり、勾配が不安定。
Truncated BPTT
逆伝播の際だけ、時系列方向のネットワークのつながりを適当に切り、それごとに学習を行う。
言語モデルの評価
予測性能の評価指標にperplexityがよく用いられる。
perplexityは確率の逆数。
youのあとにsayが来るのが正解だとする。予測したsayが来る確率が0.8ならperplexityは1.25。0.2ならperplexityは5。
perplexityは直感的には「分岐数」。つまり、次に出現しうる単語の候補数として解釈できる。
入力データが複数の場合は以下のようになる。

は確率分布(Softmaxの出力)、
はn個目のデータのk番目の値。
上式より、perplexityのlogをとるとcross entropy lossと等価。
つまりcross entropy lossを用いて学習を行うと、perplesityも小さくなる。
6章 ゲート付きRNN
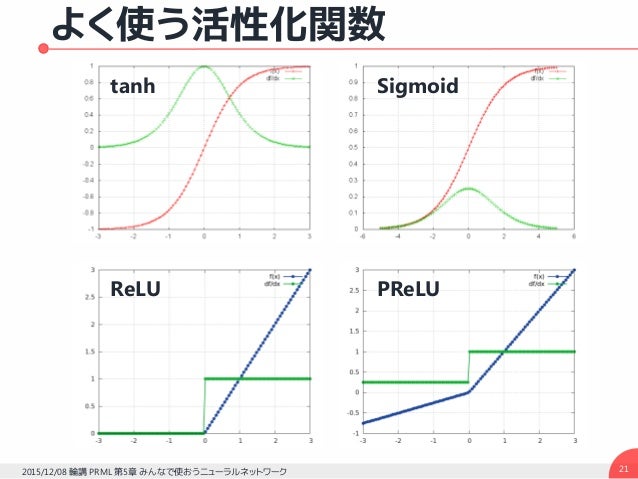
このまま、長い時系列データを与えると、勾配爆発・消失が起きる。
tanh を活性化関数にすると、微分が0〜1の範囲なので、必ず小さくなっていき、勾配消失する(ReLUだと勾配消失が起きにくいのが性能が上がる理由)。
また、重みの行列積だけ取り出して考えると、重み行列の最大特異値が1より大きいかどうかで勾配の大きさの変化が予測できる(最大特異値を使って正則化する手法がSpectral Normalizaionだったはず。好き。)。
ただ、下記論文によると、必ず予測できるとは限らないらしい。ふ〜ん。
[1211.5063] On the difficulty of training Recurrent Neural Networks
勾配爆発を抑えるためには勾配クリッピング(gradient clipping)という手法がある。
が勾配。勾配のL2ノルム
がしきい値(threshold)を超えたら上のように修正する。
勾配消失を解消するには、RNNではなくLSTMを用いる。
ここからの説明は以下のブログを参考にしているとのこと。
(元のブログの図と数式が違うけど、同じゲートを指している)
LSTMは「ゲート付きRNN」の一種。他にはGRUなどがある。
ゲートとは、データの流量をコントロールするためのもの。
LSTMは記憶セルという経路を持つ 。記憶セルは c で表す。

隠れ状態hが他のレイヤにも出力されたのに対し、cは自らのレイヤで完結する。
outputゲート

入力と
(行ベクトルとする)から求められる。
このと
との要素積を
として出力する。
forgetゲート
記憶セルは何を忘れるかも重要。その指示をする。

fが0だとc_t-1が0になるので前の記憶を失うことになる、と考えると簡単。
新しい記憶セル
forgetゲートだけだと忘却しかできないので、新しい記憶を加える。

(図の)
inputゲート
iとgの積をcに加算する。
以上がLSTMの中身。
LSTMが何やってるかってわかりづらいけど、この本の説明が一番わかりやすかった。
肝心の勾配消失について
記憶セルの伝播に注目すると
これの逆伝播を見ると、「+」では前の勾配をそのまま流すだけ。「✕」では要素積。
要素積だと勾配消失は起きにくい。
このforgetゲートによって、忘れてはいけない勾配の要素は劣化せず、忘れるべきのものだけ小さくなる、らしい。
実装にあたっては
の4式はどれもアフィン変換なので、一つの式にまとめられる。
LSTMレイヤの多層化
レイヤをでぃ〜ぷにする際には、前のレイヤの隠れ状態を次のレイヤに入力する。
Google翻訳のGNMTというモデルは8層のLSTM。
Dropout
ランダムにニューロンを無視する。
前巻ではアフィン→活性化関数の後にDropoutレイヤを挿入していた。
RNNでは、レイヤの時系列方向にDropout層を入れると、情報が失われノイズが増えて良くない。
多層化したレイヤの間(深さ方向)に入れると良いらしい。
ただ、最近は変分(variational)Dropoutなど、時系列方向に適用する手法もある、
これは、同じ深さのレイヤー間では無視するニューロンを固定するマスクをかける、というもの。
7章 RNNによる文章生成
これまで 「単語ベクトル→LSTM→Affine→Softmax with Loss→Loss」というの流れだったが、「単語ベクトル→LSTM→Affine→Softmax」まで利用することで、次に出現する単語の確率分布を出力できる。
この確率分布に応じて確率的に単語を選ぶと、試行毎に違う単語が出力される(決定的じゃない方が面白い、くらいの意味)。
確率分布からのサンプリングには np.random.choice() を使う。
これを繰り返すと文章が生成できる。
seq2seq
2つのRNNを用いて時系列データを時系列データに変換する。Encoder-Decoderモデル。
一昨年動かしてみるだけしてみたことがある。
Encoderは、時系列データを隠れ状態ベクトルにエンコードする。
Decoderは、そのを入力として単語列を出力する。
こちらでは、Softmaxの出力が一番大きい単語を用いる(決定的)。
seq2seqの改良法
Reverse
入力データを反転させると、学習が早くなり、最終的な精度も良くなる。
Peeky(覗き見)
すべての時系列でのAffineレイヤとLSTMレイヤにエンコードされたを与える(concatする)。
im2txt
seq2seqの応用例。
エンコード側をLSTMではなくCNNなどにし、出力を1次元にしてしまえば画像の特徴もキャプションにデコードできる。
8章 Attention
seq2seqの問題として、エンコードが1次元の固定長ベクトルhに圧縮されてしまうことがある。
そこで、Encoderの各時刻のLSTMレイヤの隠れ状態ベクトルをすべて利用する(結合して行列hsにする)。
これにより、単語数に応じた次元数になる。
Attention
機械翻訳において「猫=cat」のような知識を用いることをAlignmentという。これを自動化したい。
つまり、「翻訳先の単語」と対応関係にある「翻訳元の単語」を選び出したい。
ここでは、「I」を出力するとき、受け取ったhsの中から「吾輩」に対応するベクトルを選び出したい。
しかし、「選び出す」という操作は微分ができない。
①そこで、sに重み
(各単語の重要度)をかけ、重み付き和を求めることで、コンテキストベクトル
を求める。
②この重みの求め方
Decoderでは各レイヤごとに隠れ状態ベクトルが出力される。
このと
の要素を内積していくと、類似度を測れる(内積以外にも様々な手法があるらしい)。
これで各単語ごとのスコア的なものが出力されるので、あとはこれにSoftmaxを通すと、重みが求まる。
これで、上層へコンテキストベクトル(
のどの要素が重要か)を伝えることができるようになる。
Attentionの重みを可視化すると、実際に対応しているのか見ることができる(学習できてるかが、人間に理解できる)。
双方向RNN/LSTM
「吾輩 は 猫 で ある」
だと、「猫」を入力したときの隠れ状態ベクトルには「吾輩」と「は」の情報も含んでいるため、情報のばらつきがある。情報をバランスよく扱うには双方向RNN/LSTMがある。
そこで、単語列を先頭からと末尾からの2系列で入力し、その隠れ状態ベクトルを連結することで隠れ状態行列を作る。
Transformer
タイトルが有名な[1706.03762] Attention Is All You Needで提案された手法。
RNNは前時刻での結果を用いて逐次計算をするのでGPUでの並列処理に向いていない。
そこでRNNを取り除きたくなってくる。
なので実際に取り除いてみちゃいましょうというもの。
RNNの代わりにSelf-Attentionを用いる。
通常のAttentionではEncoder側のとDecoder側の
を用いる。
Self-Attentionではひとつのを用いる。
本にはあまり詳しくは載っていない。以下のブログがわかりやすかった。
Neural Turing Machine (NTM)
Attention付きseq2seqではEncoderとDecoderはAttentionを介して「メモリ操作」のようなことをしている。
つまり、Encoderが必要な情報をメモリに書き込み、Decoderはそのメモリにある情報から必要な情報を読み込んでいる、と解釈できる。
だったら、コンピュータのメモリ操作をニューラルネットで再現できるんじゃ? というもの。
LSTMレイヤを「コントローラ」とし、各時刻の隠れ状態ベクトルをWrite Headレイヤが受け取ることで外部メモリに書き込み、Read Headレイヤがメモリを読み込んで次時刻のLSTMレイヤに渡す。
このメモリ操作にAttentionを用いる。
なぜAttentionなのか。
メモリの番地を選ぶこと(W/Rともに)は微分不可能。Attentionを使い、すべての番地の「重み」を利用することで、選ぶ操作が微分可能になるから。
NTMでは「コンテンツベースのAttention」と「位置ベースのAttention」を用いる。
コンテンツベースのAttentionは今までのAttentionと同じで、あるベクトルに対して、それに似たベクトルをメモリから見つける用途。
位置ベースのAttentionは、前時刻に注目したメモリの位置(=メモリの各位置に対する重み)に対して、その前後に移動(シフト)するような用途で使われる。
詳しくは載っていないけど、1次元の畳込み演算をしているらしい。
以下のスライドがわかりやすかった。
理論背景を調べようと思ったけど、Lie群の知識とかがいるそう(吐血)。
以上で終わり。あとは付録がある。(sigmoidとtanhの微分、WordNetの動かし方、GRUについて)
これを読み終えたら、でぃ〜ぷの自然言語処理の論文も基本的なことは理解できるようになれそう。
p.s.
昨日(今日の深夜)ブログ書いてたら、はてなのメンテで内容が消えてしんどかった。
